Адаптированный перевод[1] статьи “What is a Walk-Forward Optimization and How to Run It?” Lucas Liew, размещенной на сайте Algotrading101. Суть и применение методологии Walk-Forward Optimization (WFO) для отладки торговых моделей/стратегий[2].
Содержание:
- Понятие WFO. Данные в выборке и вне выборки
- Шаг 1. Получите необходимые данные
- Шаг 2. Разбейте данные
- Шаг 3. Запустите оптимизацию на первом In-Sample
- Шаг 4. Запустите тестирование на первом Out-Sample
- Что дальше
- Walk-Forward Optimization против переобучения
- P-hacking
- Целевая функция (Objective Function)
- Размер данных в выборке и вне выборки
- Заключение
- Примечания
- Список источников
- Используемые сокращения
Понятие WFO. Данные в выборке и вне выборки
Бэктестинг стратегии дает хорошее представление о том, что происходило в прошлом, но, увы, не способен предсказать будущее. Отчасти здесь поможет метод Walk-Forward Optimization (WFO). Русская калька звучит, как “оптимизация (по принципу) “прогулки вперед”.
WFO - процесс настройки торговой стратегии, путем нахождения ее оптимальных параметров, используя данные в выборке (In-Sample Data) или обучающие данные, и проверки эффективности этих параметров в следующем периоде времени по данным вне выборки (Out-of-Sample Data) или данным тестирования.
Данные в выборке - “Прошлый сегмент рыночных данных (исторические данные), зарезервированный для целей тестирования[3]. Применяются для первоначального тестирования и любой оптимизации, являются исходными параметрами тестируемой системы”.
Данные вне выборки - “Зарезервированный набор данных (исторические данные), который не является частью данных в выборке. Это важно, так как гарантирует, что система будет протестирована на другом периоде исторических данных, и не ранее. Таким образом, устраняются отклонения или влияния при проверке производительности системы”.
Шаг 1. Получите необходимые данные
Предположим, вы хотите обучить и протестировать стратегию работы с акциями UBER и LYFT за 2015-18 годы. Подбирается полная информация о ценах этих бумаг за обозначенный период. Скажем прямо, пример не самый удачный. Трудно понять, почему выбор автора выпал на гигантов рынка мобильных приложений в области транспорта, акции которых стали обращаться на биржах только в первой половине - середине прошлого года.
Но что есть, то есть. Сам Lucas Liew невинно замечает: “Хорошо, я знаю, что UBER и LYFT не были отлистингованы в 2015 году, но давайте пофантазируем”. С другой стороны, компании уже существовали и их ценные бумаги (корпоративные права) в 2015-18 гг. могли котироваться на внебиржевом рынке. Почему нет? Вот только добыть цены акций непубличных компаний рядовому трейдеру очень непросто.
(сместить весь фрагмент чуть вправо)
Краткая справка
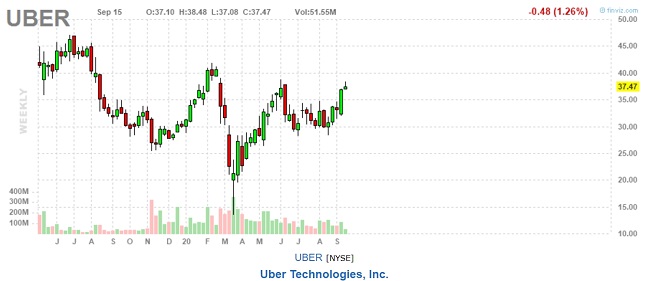
Uber Technologies, Inc. (тикер UBER), сектор Technology, отрасль Software - Application. Самая значительная райдшеринговая компания (ridesharing company) в США. Оказывает транспортные услуги с помощью мобильных приложений. Основана в 2009 году, штаб-квартира в Сан-Франциско, представлена в 900 крупнейших регионах мира. Акции входят в корзину индекса Russell 1000.
На 16.09.20 капитализация UBER $63,89 млрд, выручка $13,67 млрд, убыток $6,969 млрд. Персонал 29600 человек.
График акций UBER с июня 2019 г.:
(источник Finviz)
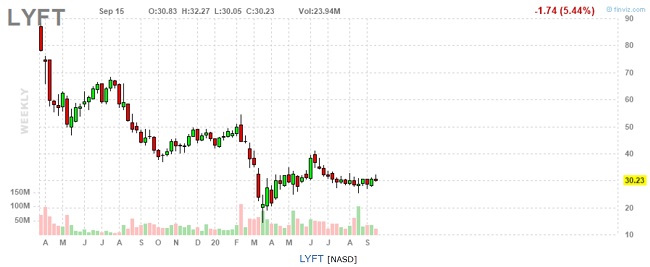
Lyft, Inc. (тикер LYFT), тот же сектор Technology, и та же отрасль Software - Application. Вторая по значимости, после UBER, американская ridesharing company. Учреждена в 2012 году, главный офис в том же Фриско. Работает в 644 городах Соединенных Штатов и в 12 городах Канады. Доля рынка - 30%.
На 16.09.20 капитализация LYFT $9,05 млрд, выручка $3,27 млрд, убыток тоже чуть пониже - $1,655 млрд. Персонал 5683 сотрудника.
График акций LYFT с апреля 2019 г.:
(источник Finviz)
Интересно, что цены обеих бумаг вполне сопоставимы. На 16.09.20 UBER и LYFT стоят $37,47 и $30,23 соответственно. Удобно при формировании портфеля. Возможно поэтому они понравились Лукасу Лью? Динамика после всемирного мартовского фондового пике у эмитентов различна. UBER смог восстановиться почти полностью, LYFT нет.
Одними котировками формирование массива данных для отладки модели может не обойтись. Так, автор предлагает использовать информацию о поисковом трафике Uber и Lyft, количество комментариев на форумах водителей поездок, индекс S&P и т. д.
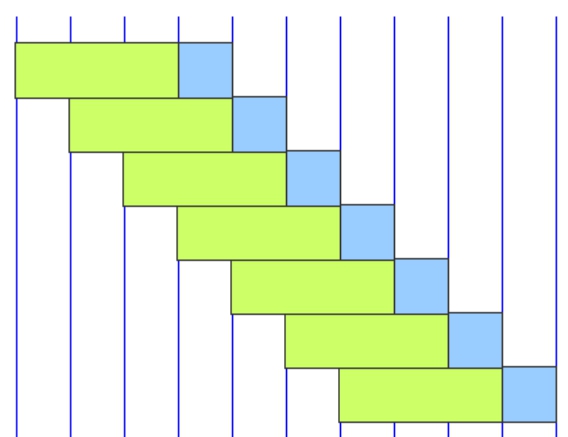
Разделим данные периода в три с половиной года, 1 января 2015 г. - 30 июня 2018 г., на семь полугодичных интервалов:

(даты, указанные на рисунке, соответствуют правым концам временных отрезков, смотрите на стрелки)
Бежевым цветом отмечены периоды для данных в выборке (In-Sample), синим - для данных вне выборки (Out-Sample). Период данных в выборке, применяемых для обучения стратегии (адаптации/оптимизации ее параметров), составляет один год. Период данных вне выборке для тестирования - полгода.
Первые данные в выборке для обучения и оптимизации (In-Sample, крайний слева бежевый прямоугольник) находятся в промежутке с 1 января по 31 декабря 2015 г.
Шаг 3. Запустите оптимизацию на первом In-Sample
Для обучения/оптимизации автор предлагает нехитрую стратегию, состоящую в покупке UBER и продаже LYFT, если на форумах райдшеринговых водителей будет больше положительных отзывов о UBER, чем о LYFT, и наоборот. Для избежания использования подобной трейдинговой модели в реале, автор самокритично именует ее, как “сильно упрощенную”.
В целях максимального облегчения, автор вводит единственный параметр стратегии, подлежащий оптимизации по WFO - количество положительных комментариев (positive comments, PC) по UBER (PCUber), деленное на число позитивных комментов по LYFT (PCLyft). Обозначим его через K(rs). Здесь под rs понимаем ridesharing, профиль обеих компаний.
Итак:
K(rs)=PCUber/PCLyft
Реальные модели задействуют более, чем один параметр, но надо помнить, что внушительный набор оптимизируемых параметров - далеко не показатель эффективности стратегии. Обычно - совсем наоборот.
Предположим, что оптимизация параметра K(rs) на данных полного 2015 года (первого периода в выборке) дала следующие настройки: UBER ставят в лонг, а LYFT в шорт, если K(rs)>2, и наоборот, шорт по UBER и лонг по LYFT, когда K(rs)<0,5. Думаю мы правильно поймем автора, если решим, что при 0,5<K(rs)<2 позиции не открываются.
Таким образом, получена первая оптимизация параметра K(rs)
Шаг 4. Запустите тестирование на первом Out-Sample
Первый период данных вне выборки (Out-Sample), крайний слева синий прямоугольник приходится на первую половину 2016 года.
Модель запускается на тестирование в интервале 01.01-30.06.2016 с первой оптимизацией параметра K(rs). Для данного отрезка времени строится своя кривая капитала (equity curve). Проверяется, как ведет себя стратегия с оптимизированным по 2015-ому году K(rs).
Шаги 3-4 повторяются.
Вторые данные в выборке для оптимизации заходят в период 01.07.2015-30.06.2016 и поглощают первый период данных вне выборки для тестирования (01.01-30.06.16). В свою очередь, период № 2 Out-Sample сдвигается во вторую половину 2016 г. (01.07-31.12.16).
И так далее, пока трейдер-экспериментатор не упрется в самую конечную дату - 30 июня 2018 года. Всего пять итераций. Следовательно, параметр K(rs) пройдет пять оптимизаций.
Успех или неуспех пройденной WFO подлежит дополнительной проверке. Система запускается на другом сегменте данных, отличных от 01.01.2015-30.06.2018. Допустим, на 01.07.2018-30.06.2020. Для надежности два сегмента обязательно не должны перекрываться.
Исходя из искусственности параметра K(rs) и ситуации с COVID-19, ударившей по рынку в марте, вряд ли шуточная стратегия Лукаса Лью будет успешной в турбулентном 2020 году. Но здесь это не имеет никакого значения. Важна процедура.
Walk-Forward Optimization против переобучения
WFO помогает, пусть отчасти, избежать переобучение системы, вредного и коварного побочного эффекта в машинном обучении, сбивающего с толку трейдеров.
“Переобучение (overfitting) в машинном обучении и статистике - явление, когда построенная модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении (на примерах из тестовой выборки).”
Тренируемая модель обрабатывает огромное количество информации, адаптирует чрезмерное число параметров, и в итоге подмечает и впитывает случайные закономерности и связи, имеющие место в обучающей выборке, но отсутствующие в генеральной совокупности[4], на реальной торговле.
Иллюстрацией переобучения служит следующий рисунок (источник 5):
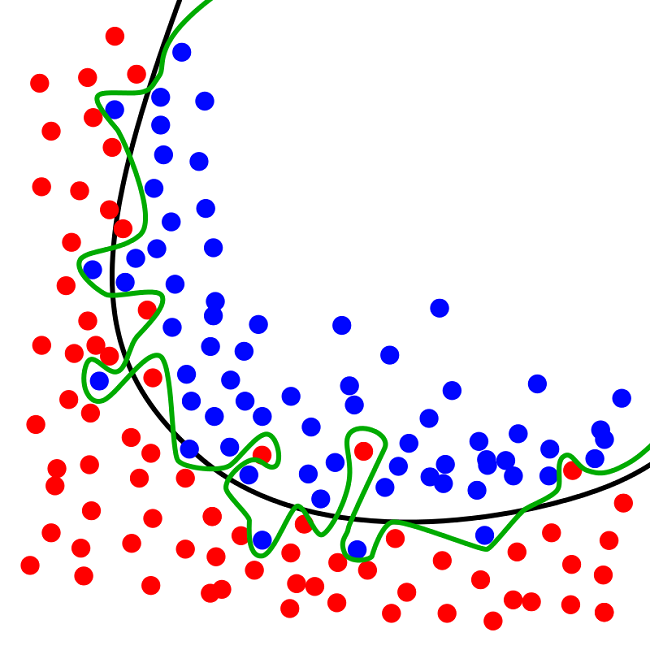
Зеленая линия отвечает переобученной модели, черная - регуляризованной[5]. Зеленая кривая лучше соответствует данным в выборке для адаптации. Но она зациклена именно на этих данных и данные вне выборки (для тестирования) будут отрабатываться системой хуже, чем если бы она следовала черной линии.
Переобучение настраивает стратегии не на сигналы, а на рыночный шум. Сигналы - полезная информация, шум отвлекает и сбивает с толку. WFO направляет модель на адаптацию параметров по сигналам из прошлого (In-Sample Data), в дальнейшем тестируя их на данных вне выборки (Out-of-Sample Data).
Начинающие алгоритмические трейдеры затрачивают массу времени на оптимизацию каждого параметра на всей прошлой исторической выборке. Затем они начинают торговать на реальном счете по таким “оптимизированным” параметрам. Обычно - это путь к краху.
К сожалению, WFO не сводит к нулю стремление системы к переобучению, а лишь ограничивает негативный процесс.
Одним из эффективных способов существенно снизить вероятность переобучения - одновременное применение Walk-Forward Optimization и P-hacking.
P-hacking известен также, как Data Dredging, Data Fishing, Data Snooping и Data Butchery. Суть коротких, и подчас, зловещих сочетаний из двух английских слов сводится в русском переводе к добыче, ловле, отслеживанию и даже “избиению” данных.
Википедия определяет Data Dredging, как “не (совсем) корректный (misuse) анализ данных для поиска закономерностей в них, которые могут представляться, как статистически значимые, путем радикального увеличения и снижения риска ложных срабатываний”. Data Dredging состоит в многократном тестировании и выявлении значимых результатов.
Лукас Лью трактует P-hacking, как анализ, проверяющий множество случайных (random) вариаций наборов параметров модели (без правильной, точной гипотезы) и отбор тех, которые работают хорошо. Что-то вроде поиска ключей или отмычек при проникновении в квартиру или подбора пароля при взломе компьютера. Слово hacking здесь вполне уместно.
Допустим, трейдер провел предварительную WFO и получил плохие отчеты. Он меняет параметры в соответствии с P-hacking.
И вновь - WFO. Опять плохо.
Процедура поиска и отладки оптимальных параметров системы в тандеме P-hacking-WFO до получения удовлетворительных результатов может включать 10-20-100 циклов.
В чем отличие P-hacking-WFO-адаптации от традиционной?
По Walk-Forward Optimization обучается и тестируется не 10 вариаций одной стратегии, что часто приводит к наводкам на шум и переобучению, а проводится 10 WFO-прогонов разных, выстроенных по методу P-hacking, моделей.
Целевая функция (Objective Function)
Walk-Forward Optimization тесно соседствует с понятием целевой функции.
Целевая функция (Objective Function) - “Вещественная или целочисленная функция нескольких переменных/параметров, подлежащая оптимизации (минимизации или максимизации) в целях решения некоторой оптимизационной задачи”.
Lucas Liew сжимает определение целевой функции к “показателю, который минимизируется/максимизируется при оптимизации”.
Самая очевидная целевая функция в трейдинге - прибыль или остаток на торговом счете (капитал, equity). Безусловно, такую целевую функцию (ее значения) следует уводить в максимальную область на исследуемой выборке.
Важным обстоятельством является учет целевой функцией поправки на риск. Заработать 1000 долларов, рискуя 2000 долларами, хуже, чем заработать 500 долларов, рискуя 100 долларами. Без поправки на риск ваша система выберет первое.
Кроме прибыли/капитала в качестве целевых функций могут выступить фактор прибыли (Profit Factor), коэффициент Калмара (Calmar Ratio) и коэффициент Шарпа (Sharpe Ratio). Подробнее об этих показателях смотрите здесь.
Размер данных в выборке и вне выборки
Размер данных в выборке должен быть относительно большим, для корректного прогноза на период вне выборки, но и не чрезмерным, чтобы не содержать много шума. Если данные в выборке слишком велики, они поглощают много ложных сигналов. Если малы, то не смогут охватить достаточно информации для удовлетворительных предсказаний.
Фактический размер зависит от выбранной торговой стратегии, от используемых инструментов и других обстоятельств.
Пример 1. Большой размер в выборке и малый вне выборки.
Обычно фьючерсы на гособлигации одного эмитента (или выпуска) двигаются синхронно, выдерживая узкий постоянный спред. Когда он расширяется, применяется стратегия парного трейдинга. Продается дорогой актив и покупается дешевый.
Большой набор данных из выборки уместен для понимания и моделирования поведения динамики облигаций. Набор данных вне выборки может быть скромнее, поскольку трейдер регулярно адаптируете свои параметры к недавнему поведению облигаций.
Пример 2. Малый размер в выборке и большой вне выборки.
Торговец полагает, что поведение акций в течение нескольких дней после объявления квартальной прибыли и ее прогнозов окажет влияние на курс бумаг в следующем квартале (3 месяца).
В данном случае, данные в выборке - несколько дней, данные вне выборки - 3 месяца.
Не ждите от Walk-Forward Optimization только положительных результатов. WFO не философский камень и не вечный двигатель.
Надо, чтобы ваша стратегия сработала тогда, когда должна, а не наоборот. Например. вы не хотите, чтобы трендовая стратегия действовала, при запуске в период ранжирования (ranging period).
\Ищите закономерности. Если ваша производительность снижается со временем, это признак того, что стратегия теряет свою эффективность.
перевод и обработка Владимира Наливайского
В основе изложения - материал “What is a Walk-Forward Optimization and How to Run It?” Lucas Liew, Algotrading101, 24.06.2020. По тексту Lucas Liew (Лукас Лью) может фигурировать, как автор.
В подготовке статьи использованы данные сайта Finviz.com
Источник изображения на заставке - статья “Guide to Walk Forward Testing and Optimization (How to Use Walk Forward in Trading)”, The Robust Trader.
Первоисточниками определений терминов, понятий, явлений, вводимых по тексту, являются профильные статьи Википедии/Wikipedia, указанные в Списке источников к публикации (для переводов - возможны трактовки автора исходного материала) если не оговорено иное.
- Под адаптированным переводом понимается достаточно точное следование исходному материалу с возможными отступлениями и пояснениями. Конкретные вещи - формулы, скрипты и пр. (и комментарии к ним) изложены максимально близко к оригиналу (скопированы). Ответственность за их корректность и ясность интерпретации несет автор исходника.
- По тексту понятия “модель, стратегия и система” выступают как синонимы.
- По тексту понятия “обучение, тестирование и адаптация/оптимизация (параметров)” выступают как синонимы.
- Генеральная совокупность - совокупность всех объектов (единиц), относительно которых предполагается делать выводы при изучении конкретной задачи. Смотрите источник 6.
- Регуляризация в статистике, машинном обучении, теории обратных задач - метод добавления некоторых дополнительных ограничений к условию с целью решить некорректно поставленную задачу или предотвратить переобучение. Эта информация часто имеет вид штрафа за сложность модели. Смотрите источник 7. В известном смысле, WFO можно рассматривать, как вариант регуляризации.
Список источников (Википедия/Wikipedia, если не оговорено иное)
- “Walk forward optimization”.
- “Uber”.
- “Lyft”.
- “Ridesharing company”.
- “Переобучение”.
- “Генеральная совокупность”.
- “Регуляризация (математика)”.
- “Целевая функция”.
- “Data dredging”.
WFO - Walk forward optimization